Intraday Intensity and Chaikin's Money Flow
The first volume-oriented indicator for the toolbox. Test results are promising: 1.6 profit factor on threshold tests.

Disclaimer: the following post is an organized representation of my research and project notes. It doesn’t represent any type of advice, financial or otherwise. Its purpose is to be informative and educational. Backtest results are based on historical data, not real-time data. There is no guarantee that these hypothetical results will continue in the future. Day trading is extremely risky, and I do not suggest running any of these strategies live.
Ever heard of the Intraday Intensity Indicator? What about Chaikin's Money Flow?
Me either. Until recently, that is.
In the past several months we have discussed indicators for determining trend, momentum, and volatility. Many of those indicators can use volume information in their calculations, but they aren't specifically tuned to be volume indicators. Volume indicators are designed to tell us specifically about volume behavior.
What can volume tell us, you ask?
A lot, but we are going to start simple. Wouldn't it be cool if you knew whether the current price activity is being driven high-volume institutional trades? Well, that's exactly what David Bostian's Intraday Intensity Indicator is designed to do and it happens to be the base for the indicator that we are going to create today.
The Intraday Intensity Index (III) was originally developed by David Bostian to help determine how much volume is influencing a security's price. The formula for calculating this indicator on a single bar looks like:
According to Masters, there are several prominent websites who have this calculation wrong. [1] I almost linked one of them above for the III definition. He also points out that multiplying the answer by 100 isn't necessary, but makes it a little easier to read. None of that really matters though, because he goes on to point out that the indicator has a couple of flaws that make it useless for automated trading (and arguably manual trading). [1]
These flaws are:
The raw value isn't normalized and is known to fluctuate wildly.
Most assets do not maintain the same volume year by year. This value typically rises, making the indicator extremely nonstationary.
For those reasons, we turn our eyes to Chaikin's Money Flow (CMF) indicator, which builds on the base of the III and adds a level of normalization that can be used with machine models without the need for further normalization. The original CMF was created by Marc Chaikin with a window of 21 days, but the variation that we are going to discuss here is purpose built for using in financial market prediction models and comes from reference one.
The formula for the CMF that we will discuss looks like this:
This formula shows that we divide the smoothed values of the III with a smoothed measure of volume. This helps normalize the raw value and induce stationarity well enough that there is no need to add any more steps. A different way, and perhaps easier to read for traders, to express this equation is with the following formula:
It's important to note that the use of the EMA for the volume is not always agreed upon by other quants or traders.[1] The equation before this one shows the "accepted" equation using simple smoothing for both the II value and the volume. The numerator and denominator are the lookback windows for the MA and EMA. In the code below, we will allow the user the ability to adjust either of these options as they see necessary.
Validation and Optimization Tests
The generated report provides a comprehensive analysis of trading indicators, offering insights into their statistical properties, predictive power, mean stability over time, and optimal thresholds for profitability. It combines detailed statistical summaries, mutual information scores, mean break tests, and profit factor evaluations.



Simple Statistics and Relative Entropy Report
The Simple Statistics Table summarizes key metrics for each trading indicator, including the number of cases, mean, minimum, maximum, interquartile range (IQR), range/IQR ratio, and relative entropy. In the table, a lower range/IQR ratio suggests a tighter, more predictable dataset, while an optimal relative entropy indicates a balance of diversity and uniqueness without excessive noise.
Ncases: Number of cases (bars) in feature (indicator).
Mean: Average value of the feature across all cases.
Min/Max: The minimum and maximum value of the feature across all cases.
IQR: Interquartile Range, measures range minus the top and bottom 25% of the raw range.
Range/IQR: A unitless measure of data dispersion relative to its middle 50%.
Relative Entropy: Measures the difference between two probability distributions; a value of zero indicates identical distributions.

Mutual Information Report
High MI scores indicate a strong relationship between the indicator and the target variable, suggesting potential predictive power. Low p-values further validate the indicator's statistical significance.
MI Score: Measures the mutual dependence between the feature and the target.
Solo p-value: Initial significance estimate, proportion of permuted MI scores equal to or higher than the original MI scores.
Unbiased p-value: Adjusted solo p-value considering the number of permutations plus one, reducing bias.

Serial Correlated Mean Break Test Report
The Serial Correlated Mean Break Test Report identifies potential breaks in the mean of each trading indicator, taking into account serial correlation. This test helps detect significant shifts in the mean over time, indicating nonstationary behavior in the data.
nrecent: The number of recent observations considered in the test.
z(U): The greatest break encountered in the mean across the user-specified range.
Solo p-value: Measures the significance of the greatest break while accounting for the entire range of boundaries searched. If this value is not small, it suggests that the indicator does not have a significant mean break.
Unbiased p-value: Adjusted solo p-value considering the number of permutations plus one, reducing bias.

Optimal Thresholds w/ Profit Factor Report
The Optimal Thresholds w/ Profit Factor Report evaluates various threshold levels for trading indicators to identify the most profitable long and short positions. The report includes the fraction of data points greater than or equal to the threshold, the corresponding profit factor for long and short positions, and the fraction of data points less than the threshold with their respective profit factors. The optimal thresholds at the bottom indicate the threshold levels with the highest profit factors for long and short positions, while the p-values provide statistical significance for these thresholds.
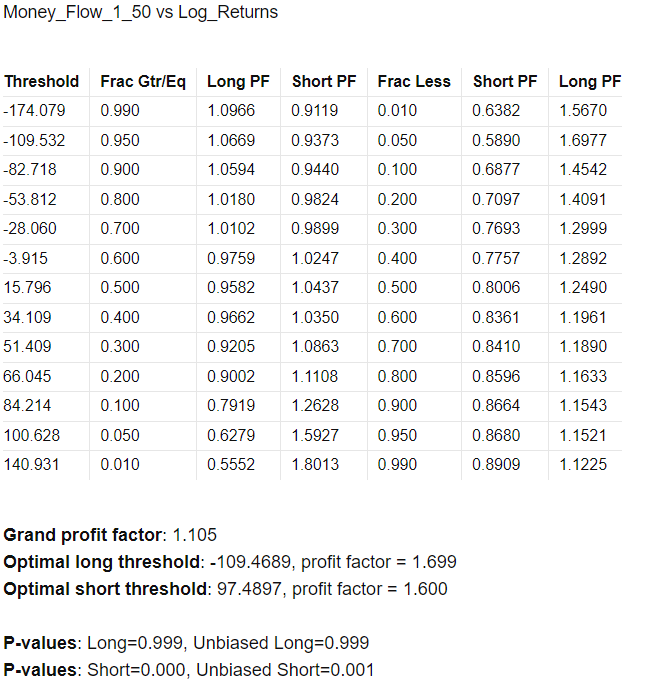


Note: I need to look at the p-value calculations in the optimization reports. I am fairly certain there is something simple wrong with the calculations for the long-side profit factor.
Code
Since this function is intended to be used in trade system research and prediction models, I do not code it in a way that we can obtain the raw value. Since it is not technically the III or the CMF indicator, I just call it money_flow. This indicator uses a simple moving average function and exponential moving average function that are defined elsewhere.
import numpy
from pqt.MathFunc import MA, EMA
def money_flow(close, high, low, volume, lookback, n_to_smooth=None):
"""
Chaikin's Money Flow indicator.
Parameters:
- close: np.array, array of close prices
- high: np.array, array of high prices
- low: np.array, array of low prices
- volume: np.array, array of volume data
- lookback: int, the lookback period for calculating moving averages
- n_to_smooth: int, optional, the lookback period for exponential smoothing (default None)
Returns:
- output: np.array, array of Chaikin's Money Flow values
"""
n = len(close)
# Ensure volume is non-zero, start calculation from the first non-zero volume
first_volume = np.argmax(volume > 0)
front_bad = lookback - 1 + first_volume
# Calculate raw money flow
output = np.zeros(n)
valid_mask = (high > low)
output[valid_mask] = 100.0 * (2.0 * close[valid_mask] - high[valid_mask] - low[valid_mask]) / (high[valid_mask] - low[valid_mask]) * volume[valid_mask]
if lookback > 1:
output = MA(output, lookback)
# Apply volume smoothing (optional) using fast_exponential_smoothing
if n_to_smooth and n_to_smooth > 1:
smoothed_vol = EMA(volume, lookback=n_to_smooth)
output[first_volume:] = np.where(smoothed_vol[first_volume:] > 0, output[first_volume:] / smoothed_vol[first_volume:], 0.0)
# Set undefined values to 0.0
output[:front_bad] = 0.0
return outputRealTest:
Parameters:
numer: 1
denom: 50
Data:
II: (2 * Close - High - Low) / (High - Low) * Volume
II_smoothed: MA(II, numer)
V_smoothed: EMA(Volume, denom)
money_flow: 100 * (II_smoothed / V_smoothed)Conclusion
Don't you love how simple it is to create this indicator in RealTest? Those test results aren't bad either. I think this is going to be a fun indicator to use in strategy research.
The MA and EMA functions in the code can be found in the GitHub repo if you are a paid subscriber. Free subscribers, you can just plug in your own EMA or MA functions here or use something from the TA-Lib · PyPI library. There is nothing fancy going on there.
Strategy 11 is next in line. It should be out by the end of this week.
Stay safe out there this week.
Happy Hunting!
The code for strategies and the custom functions/framework I use for strategy development can be found at the Hunt Gather Trade GitHub. This code repository will house all code related to articles and strategy development. If there are any paid subscribers without access, please contact me via e-mail. I do my best to invite members quickly after they subscribe. That being said, please try and make sure the e-mail you use with Substack is the e-mail associated with GitHub. It is difficult to track members otherwise.
Feel free to comment below or e-mail me if you need help with anything, wish to criticize, or have thoughts on improvements. Paid subscribers can access this code and more at the private HGT GitHub repo. As always, this newsletter represents refined versions of my research notes. That means these notes are plastic. There could be mistakes or better ways to accomplish what I am trying to do. Nothing is perfect, and I always look for ways to improve my techniques.
References
Masters, T. (2013). Statistically sound indicators for financial market prediction.