The QP -- A Python interpretation of the Quantitativo Probability Indicator
This indicator came from the Quant Trading Rules newsletter. It's a mean reversion indicator with some good test results.

Disclaimer: the following post is an organized representation of my research and project notes. It doesn’t represent any type of advice, financial or otherwise. Its purpose is to be informative and educational. Backtest results are based on historical data, not real-time data. There is no guarantee that these hypothetical results will continue in the future. Day trading is extremely risky, and I do not suggest running any of these strategies live.
Today's post wasn't a planned post. I found myself looking at a mean reversion indicator that a subscriber showed me in the following article by Quantitativo:
In this article, the author explains how to calculate a mean reversion indicator using relative measures of returns. At first, I attempted to create this indicator in RealTest, after a subscriber mentioned it to me and asked if I had seen the forum thread about it. I hadn't seen it, but I thought it was interesting so I decided to take a stab at it. My first version was only part of the calculation though, so I decided to build it out in Python first and then come back to the RealTest version.
After it was all said and done, I had created a new function for the pqt library, created the indicator, learned about vectorization, refactored for vectorization, and tested the indicator for soundness. Then, I went back and completed it in RealTest. I haven't tested the functionality in RealTest yet, but I am wondering if this indicator might be a good complement to Strategy 9 for some short exposure.
I am posting the concept and code for this indicator to all readers/subscribers. The original concept for this indicator comes from the Quantitativo Substack, which appears to post everything for free. It is awesome to see that you can find good information for free on this subject, so I intend to do the same with this indicator.
This post will cover the following:
Coding the
PercentRank()function in Python.Coding/refactoring the
ATR()function in Python.Coding the
QP()indicator in Python and RealTest Script
Let's dig in.
Creating the QP Indicator
The concepts for this indicator are pretty simple. I am going to write out the criteria below but understand that this is my interpretation of the logic. If you want to see it as written originally, check out the article linked at the beginning of this post. There is always a possibility that I have gotten some part wrong.
Here is an excerpt from the article explaining the criteria:
We look back 5 years from the given date and get all 3-day returns in this period;
Then, we get the percentile of the 3-day price change on the given date if the 3-day price change is negative (or 100 minus the percentile if the 3-day price change is positive);
Finally, we divide this value by the area at the left of the zero in the histogram if the 3-day price change is negative (or at the right if it is positive) and multiply by 100.
The equation for the QP looks something like this:
with the area equation looking like this:
or
Before we can code this indicator, we need to create the Percent Rank and Average True Range functions.
Percent Rank
Calculates the percent rank of a target value within a target array. The function first sorts the target array in ascending order. It then determines the rank of the target value relative to the sorted array, with the lowest value receiving a percent rank of 0% and the highest value receiving a percent rank of 100%.
If there is only one value in the target array, the function returns 100% for that value. The attempt is to mimic the RealTest, and subsequently the Excel, functionality.
Parameters:
target_value (float): The value for which the percent rank is to be calculated.
target_array (numpy.ndarray): An array of float values (e.g., returns or close prices) among which the percent rank of the target_value is determined.
Returns:
float: The percent rank of the target_value within the target_array. The rank will be between 0% and 100%, with 0% representing the lowest value and 100% representing the highest value in the array.
Formula:
PercentRank Code:
@jit(nopython=True)
def PercentRank(target_value, target_array):
n = len(target_array)
sorted_indices = np.argsort(target_array)
sorted_array = target_array[sorted_indices]
rank = np.searchsorted(sorted_array, target_value, side='right')
percent_rank = (rank - 1) / (n - 1) * 100 if n > 1 else 100.0
return percent_rank
CopyAverage True Range (ATR)
Calculate the most recent Average True Range (ATR) value using either standard or logarithmic returns.
Parameters:
high_prices (np.ndarray): Array of high prices.
low_prices (np.ndarray): Array of low prices.
close_prices (np.ndarray): Array of close prices.
period (int): The number of periods over which to calculate the ATR (default is 252).
use_log (bool): If True, calculates the true range using logarithmic returns.
Returns:
float: The most recent ATR value.
Formula:
ATR Code:
@jit(nopython=True)
def atr(high_prices, low_prices, close_prices, period=252, use_log=True):
# Calculate the logarithmic returns or standard differences
if use_log:
high_log = np.log(high_prices[1:] / high_prices[:-1])
low_log = np.log(low_prices[1:] / low_prices[:-1])
close_log = np.log(close_prices[1:] / close_prices[:-1])
tr1 = high_log - low_log
tr2 = np.abs(high_log - close_log)
tr3 = np.abs(low_log - close_log)
else:
tr1 = high_prices[1:] - low_prices[1:]
tr2 = np.abs(high_prices[1:] - close_prices[:-1])
tr3 = np.abs(low_prices[1:] - close_prices[:-1])
# Calculate the True Range as the maximum of tr1, tr2, tr3
true_ranges = np.maximum(np.maximum(tr1, tr2), tr3)
# Calculate the ATR value as the mean of the last 'period' true ranges
atr_value = np.mean(true_ranges[-period:])
return atr_value
CopyQuantitativo Probability
At last, we arrive at the QP. Since I tend to use log returns for most of my testing and research, I decided to do the same here. This function calculates the Quantitativo's Probability (QP) indicator for the most recent data point using log returns. The returns are normalized with the ATR(252) and the percent rank divided by the area of the returns in question in order to return a number between 1 and 100.
Note:
I did not multiply the final product by 100 as our result is already between 1 and 100 without it. I believe the original method did so because it was using the percentage/fractional method of returns and not log returns. I could also just be wrong.
Parameters:
target_high (np.ndarray): Array of high prices for the target security.
target_low (np.ndarray): Array of low prices for the target security.
target_close (np.ndarray): Array of close prices for the target security.
window (int): The number of days for the price change window (default is 3).
lookback (int): The number of days to look back for the histogram (default is 1260).
Returns:
float: The QP indicator value for the most recent price.
QP Code:
@jit(nopython=True)
def QP(target_high, target_low, target_close, window=3, lookback=1260):
"""
Calculate the Quantitativo's Probability (QP) indicator for the most recent data point using log returns.
Parameters:
- target_high (np.ndarray): Array of high prices for the target security.
- target_low (np.ndarray): Array of low prices for the target security.
- target_close (np.ndarray): Array of close prices for the target security.
- window (int): The number of days for the price change window (default is 3).
- lookback (int): The number of days to look back for the histogram (default is 1260).
Returns:
- float: The QP indicator value for the most recent price.
"""
n = len(target_close)
# Replace zeros in target_close with epsilon
target_close = np.where(target_close == 0, 1.e-20, target_close)
# Calculate the ATR value for normalization
atr252 = atr(target_high, target_low, target_close, period=252)
# Calculate daily log returns and normalize by ATR
daily_returns = np.log(target_close[1:] / target_close[:-1]) / atr252
# Calculate the 3-day cumulative log returns using a rolling window sum
returns = np.convolve(daily_returns, np.ones(window), 'valid')
# Reverse the array to have the most recent return at index [0]
returns = returns[::-1]
# Extract the most recent return
recent_return = returns[0]
# Calculate the QP value based on the most recent return
if recent_return <= 0:
# Count the number of negative returns within the lookback period
neg_returns_count = np.sum(returns[:lookback] <= 0)
total_count = len(returns[:lookback])
# Area as the ratio of the count of negative returns to the total count
area_left_of_zero = neg_returns_count / total_count if total_count != 0 else 1.e-20
# Calculate Percentile Rank
pctrank = PercentRank(recent_return, returns[:lookback])
# Normalize by dividing by the "area"
raw_qp = pctrank / area_left_of_zero
else:
# Count the number of positive returns within the lookback period
pos_returns_count = np.sum(returns[:lookback] > 0)
total_count = len(returns[:lookback])
# Area as the ratio of the count of positive returns to the total count
area_right_of_zero = pos_returns_count / total_count if total_count != 0 else 1.e-20
# Calculate Percentile Rank
pctrank = PercentRank(recent_return, returns[:lookback])
# Normalize by dividing by the "area"
raw_qp = (100 - pctrank) / area_right_of_zero
return raw_qpRealTest Script:
This is how I am currently implementing this indicator in real test.
atr252: Sum(TR, 252) / 252
log_returns: Log(C / C[1])
returns: Sum(log_returns, window) / atr252
pctreturns: C / C[3] - 1
negreturns: IF(returns <= 0, returns, nan)
posreturns: IF(returns > 0, returns, nan)
pctrank: IF(returns <= 0, PercentRank(negreturns, 1260), 100 PercentRank(posreturns, 1260))
pos_count: Sum(!IsNaN(posreturns), lookback)
neg_count: Sum(!IsNaN(negreturns), lookback)
area: IF(returns <= 0, neg_count / lookback, pos_count / lookback)
qpi: IF(returns <= 0, pctrank / area, 100 - pctrank / area)Indicator Soundness Report
The generated report provides a comprehensive analysis of trading indicators, offering insights into their statistical properties, predictive power, mean stability over time, and optimal thresholds for profitability. It combines detailed statistical summaries, mutual information scores, mean break tests, and profit factor evaluations.
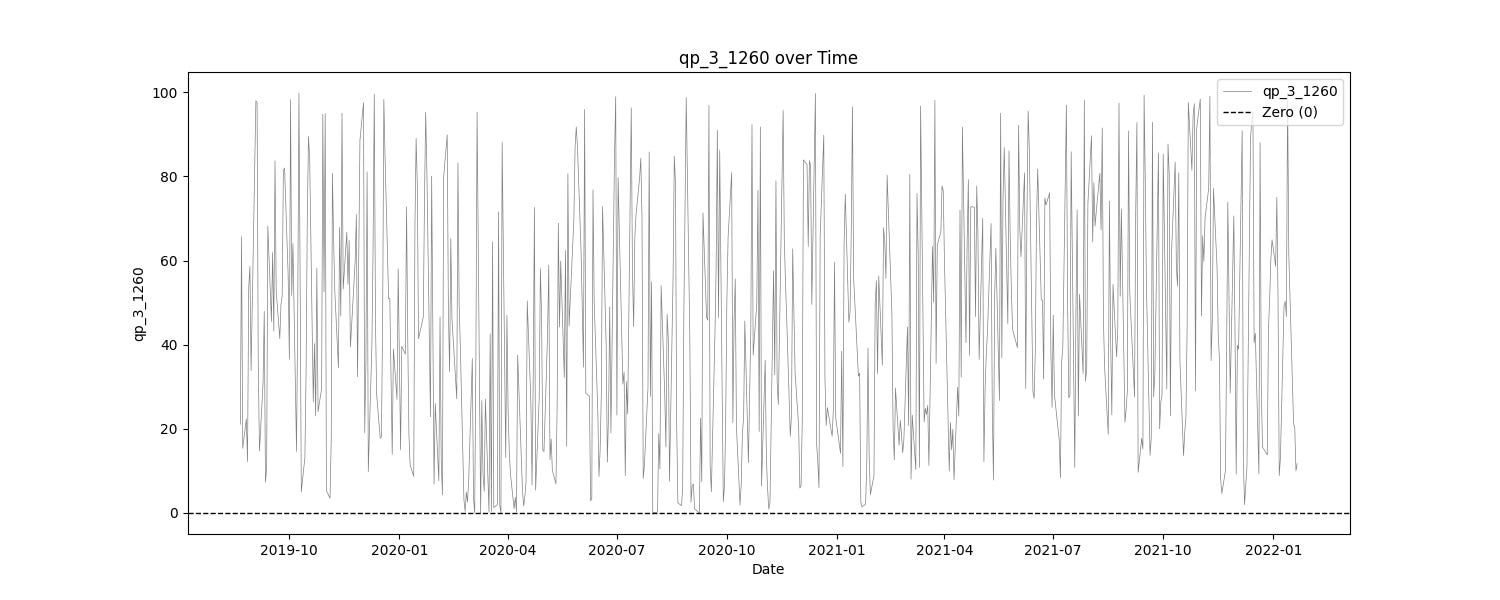
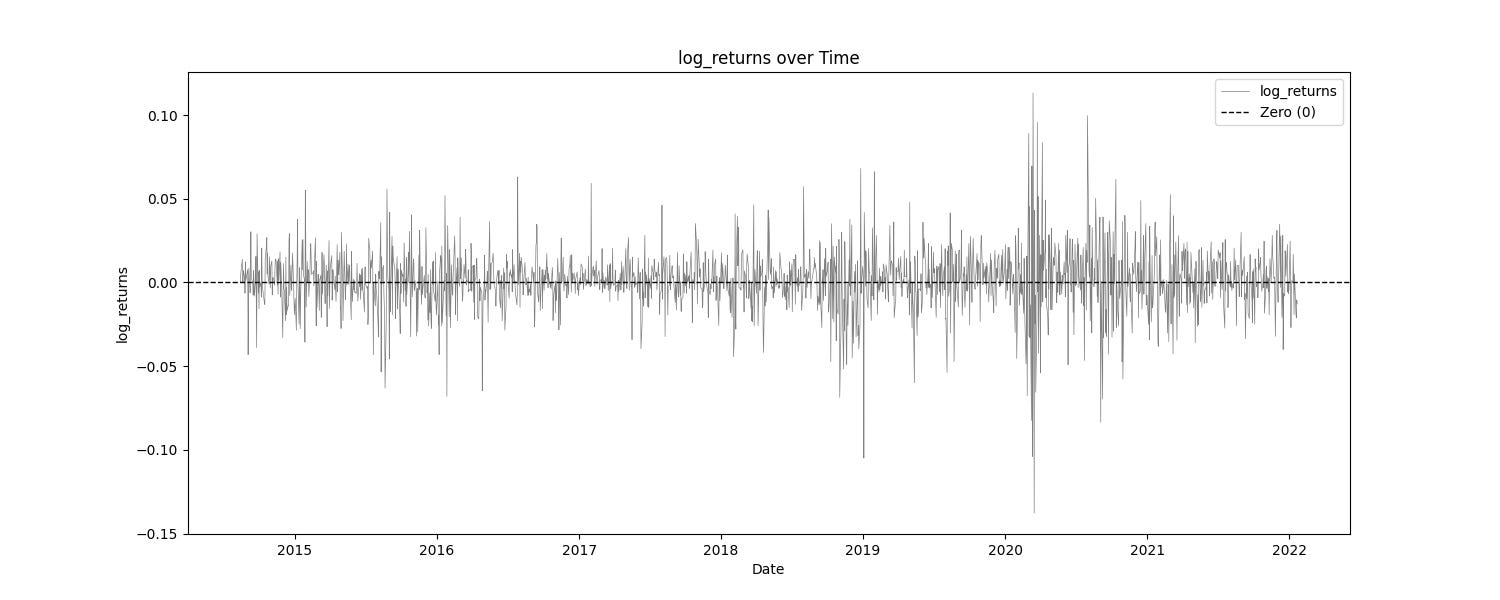
Simple Statistics and Relative Entropy Report
The Simple Statistics Table summarizes key metrics for each trading indicator, including the number of cases, mean, minimum, maximum, interquartile range (IQR), range/IQR ratio, and relative entropy. In the table, a lower range/IQR ratio suggests a tighter, more predictable dataset, while an optimal relative entropy indicates a balance of diversity and uniqueness without excessive noise.
Ncases: Number of cases (bars) in feature (indicator).
Mean: Average value of the feature across all cases.
Min/Max: The minimum and maximum value of the feature across all cases.
IQR: Interquartile Range, measures range minus the top and bottom 25% of the raw range.
Range/IQR: A unitless measure of data dispersion relative to its middle 50%.
Relative Entropy: Measures the difference between two probability distributions; a value of zero indicates identical distributions.
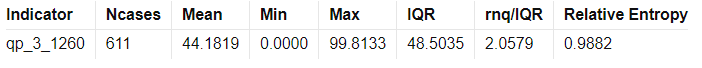
Mutual Information Report
High MI scores indicate a strong relationship between the indicator and the target variable, suggesting potential predictive power. Low p-values further validate the indicator's statistical significance.
MI Score: Measures the mutual dependence between the feature and the target.
Solo p-value: Initial significance estimate, proportion of permuted MI scores equal to or higher than the original MI scores.
Unbiased p-value: Adjusted solo p-value considering the number of permutations plus one, reducing bias.

Serial Correlated Mean Break Test Report
The Serial Correlated Mean Break Test Report identifies potential breaks in the mean of each trading indicator, taking into account serial correlation. This test helps detect significant shifts in the mean over time, indicating nonstationary behavior in the data.
nrecent: The number of recent observations considered in the test.
z(U): The greatest break encountered in the mean across the user-specified range.
Solo p-value: Measures the significance of the greatest break while accounting for the entire range of boundaries searched. If this value is not small, it suggests that the indicator does not have a significant mean break.
Unbiased p-value: Adjusted solo p-value considering the number of permutations plus one, reducing bias.

Optimal Thresholds w/ Profit Factor Report
The Optimal Thresholds w/ Profit Factor Report evaluates various threshold levels for trading indicators to identify the most profitable long and short positions. The report includes the fraction of data points greater than or equal to the threshold, the corresponding profit factor for long and short positions, and the fraction of data points less than the threshold with their respective profit factors. The optimal thresholds at the bottom indicate the threshold levels with the highest profit factors for long and short positions, while the p-values provide statistical significance for these thresholds.

The results from the indicator tests are quite interesting, but it would be really nice to see this done with at least 10 more years of data about 10x the number of permutations.
Conclusion
I hope you enjoyed it. If you are a paid subscriber, these functions can be found in the GitHub repository. If you aren't a paid subscriber and you would like access to the GitHub and all the paid articles on this Substack make sure to subscribe. I am working steadily on building up the Python toolbox and I've got several strategies I want to test and get out to the community. Becoming a paid subscriber helps me devote more time to building our tools and researching concepts to help you hone your craft.
Happy hunting!
The code for strategies and the custom functions/framework I use for strategy development in Python and NinjaScript can be found at the Hunt Gather Trade GitHub. This code repository will house all code related to articles and strategy development. If there are any paid subscribers without access, please contact me via e-mail. I do my best to invite members quickly after they subscribe. That being said, please try and make sure the e-mail you use with Substack is the e-mail associated with GitHub. It is difficult to track members otherwise.
Feel free to comment below or e-mail me if you need help with anything, wish to criticize, or have thoughts on improvements. Paid subscribers can access this code and more at the private HGT GitHub repo. As always, this newsletter represents refined versions of my research notes. That means these notes are plastic. There could be mistakes or better ways to accomplish what I am trying to do. Nothing is perfect, and I always look for ways to improve my techniques.
Awesome, thanks for that!